The first breakout session I attended was the most interesting. It was titled "iPhone User Interface Design."
The first point the presenter made was that the percentage of time that you spend on portions of the development cycle is quite a bit different for a successful iPhone app than most software applications. He showed a diagram that looked way cooler than this:
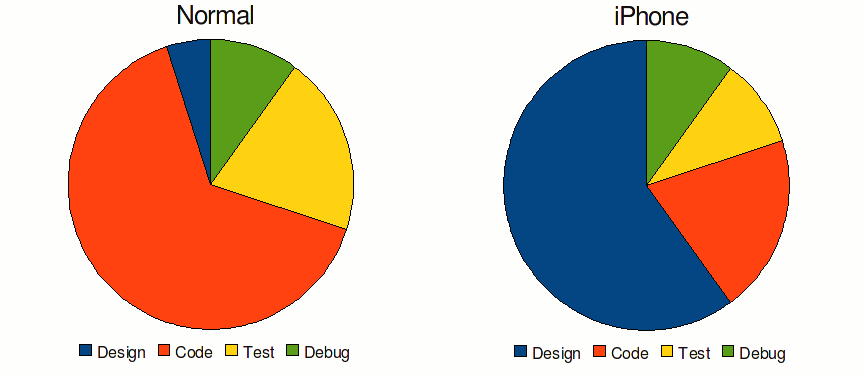
What this means is that you need to spend a lot more time in the design aspects of your app throughout the life cycle than you normally would. This set the tone for the rest of the presentation.
He defined "design" as mapping out requirements, doing the art and layout, and figuring out how core features and navigation are going to work. The cycle for developing a new product should typically go: familiarize, conceptualize, realize, finalize. Executing these well will take your application from average to excellent.
Familiarize
One solid suggestion was to read through Apple's Human Interface Guide. Apple has spent a lot of time thinking about how people will interact with the iPhone and iPod Touch, so you don't need to duplicate their work. What's more, there are many conventions that you will be unaware of and unwittingly break. For example, Apple intends all buttons to have rounded corners, so if you have something that's not a button, don't make it rounded. Likewise, buttons should look like buttons because users have a model of what a button looks like and what it does.
The presenter reiterated considerations voiced in the general session, such as thinking about where the user will use the application and considering general properties of the iPhone and how it differs from the web and from a desktop computer.
One significant suggestion was to design for the thirty-second use case. You need to consider that the user wants to open your app and get what they need within thirty seconds. If your app has a bunch of meaningless screens or has poor performance, it will significantly hinder your ability to help them. If it takes twenty seconds to navigate where they need to go, you only have ten seconds to please them. If you can save any time by remembering or determining data (zip code for searching for restaurants, for instance), you should do that. It takes a lot of time and mental effort to type things in on the iPhone, and it would be very annoying if the user has to type something in multiple times.